Algorytmy sortowania i ich realizacje w Python 3
Przedstawiam bardzo treściwy, gościnny artykuł na temat sortowania opracowany specjalnie dla Was przez Kubę i Marcela! Gratuluję autorom chęci podzielenia się wiedzą ze światem oraz przede wszystkim świetnie wykonanej roboty i zapraszam do lektury - zaczynajmy!
Spis treści
- Początki sortowania, od czego się zaczęło?
- Co by było, gdybyśmy nie używali sortowania?
- Wymagana wiedza przed nauką algorytmów
- Złożoność obliczeniowa
- Pseudokod i składnia języka Python 3
- Algorytmy sortowania
- Iteracyjne
- Sortowanie bąbelkowe
- Sortowanie kubełkowe
- Rekurencyjne
- Sortowanie przez scalanie
- Sortowanie szybkie
- Zadania do przećwiczenia
- Przykładowe zastosowanie sortowań na maturze z informatyki
- Zakończenie

Początki sortowania, od czego się zaczęło?
Początki sortowania można odnaleźć w pradawnych czasach, kiedy to ludzie zaczęli grupować przedmioty na podstawie ich kształtu, rozmiaru lub użyteczności. To były początki nieświadomego sortowania.
W czasach starożytnych Grecji i Rzymu, ludzie zaczęli rozwijać bardziej zaawansowane metody sortowania, szczególnie w kontekście bibliotek i zbiorów dokumentów. W tamtych czasach stosowano różne techniki, takie jak sortowanie alfabetyczne czy według tematu.
Średniowiecze nie przyniosło wiele zmian, natomiast powstawały pierwsze katalogi książek i dokumentów, które pomagały w ich odnajdywaniu. Jednak techniki sortowania wciąż były oparte głównie na pracy ręcznej.
Dopiero po II wojnie pojawiły się pierwsze algorytmy. W 1956 roku zaprezentowano sortowanie bąbelkowe, a w 1959 sortowanie szybkie.
Co by było, gdybyśmy nie używali sortowania?

Życie bez sortowania byłoby znacznie bardziej skomplikowane i mniej efektywne, zarówno w kontekście codziennym, jak i w dziedzinach naukowych, biznesowych czy technologicznych. Sortowanie jest nieodłącznym elementem, które znacząco ułatwia nasze życie.
Wyobrażasz sobie na chwilę proces wysyłki towarów i przesyłek bez jakiejkolwiek formy sortowania. Dla wielu osób byłoby to niezwykle frustrujące i czasochłonne doświadczenie. Przesyłki byłyby porozrzucane przypadkowo, co sprawiłoby, że odnalezienie konkretnej paczki zajęłoby dużo czasu, a koszty logistyczne znacząco wzrosłyby z powodu braku organizacji.
Podobnie, gdyby sklepy nie uporządkowały towaru według kategorii, jak np. artykuły papiernicze czy nabiał, zakupy stałyby się bardziej żmudne i trudne. Klienci musieliby przeszukiwać cały sklep, aby znaleźć potrzebne produkty, co wydłużyłoby czas spędzony na zakupach i stworzyłoby chaos w sklepach.
Sortowanie jest kluczowym elementem naszej organizacji społecznej i cywilizacji. Ułatwia nam życie, pozwalając na efektywną organizację i zarządzanie zarówno w obszarze logistyki, handlu, jak i wielu innych dziedzinach naszego życia.
Naukowcy wymyślili wiele skutecznych sposobów, które radzą sobie z tym tematem. Kilka z nich chcemy wam przedstawić i pokazać implementację w języku Python 3.
Wymagana wiedza przed nauką algorytmów.

Przed przystąpieniem do nauki algorytmów oraz analizy naszych kodów należy upewnić się, że dobrze opanowało się poniższe zagadnienia. Będą one potrzebne do całkowitego zrozumienia poruszanych przez nas tematów.
Złożoność obliczeniowa.
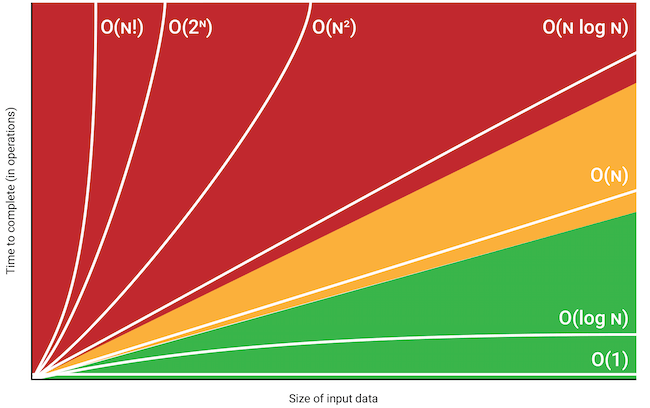
Jest to miara zużycia zasobów. Zasobem może być czas, pamięć lub liczba porównań. Wyraża się ją w notacji dużego O. Przykłady złożoności obliczeniowej:
- O(n),
- O(n!),
- O(n2).
Najpierw zapisywana jest wielka litera O. Jest to podkreślenie, że w zapisie chodzi nam o przedstawienie złożoności obliczeniowej.
Litera n wskazuje na liczbę elementów, na których przeprowadzane są instrukcje, np. sortowanie.
W zapisie może pojawić się operacja - potęgowanie, silnia, logarytm. Wynik działania informuje nas o całkowitym zużyciu zasobów.
Przykład:
Badamy złożoność obliczeniową algorytmu, w którym zasobem będzie liczba porównań. Algorytm ma złożoność obliczeniową O(n2). Przy 8 elementach (n = 8) całkowite zużycie zasobów wyniesie 82 = 64.
Ostatecznie algorytm wykona 64 porównania.
Pseudokod i składnia języka Python 3
Aby można było wykorzystać zdobytą w tym artykule wiedzę, powininno się znać pseudokod lub dobrze opanować język programowania. Na maturę polecamy język Python w wersji 3 ze względu na jego prostą składnię, czytelność, funkcje oraz różnorodność bibliotek. Wszystkie algorytmy zostały napisane właśnie w tym języku.
W tabeli dodano dodatkowo instrukcje w pseudokodzie odpowiadające tym z Pythona.
Krótka powtórka:
| Pseudokod | Python | |
|---|---|---|
| Deklaracja zmiennej i przypisanie |
x ← 3 | x = 3 |
| Instrukcja warunkowa i porównanie |
jeżeli (x = 3) x ← x - 3 w przeciwnym razie x ← x + 3 |
if x == 3: x -= 3 # x = x - 3 else: x += 3 # x = x + 3 |
| Pętla for | dla i ← 0 do 9 wykonuj x ← x*x |
for i in range(10): x = x*x |
| Pętla while | i ← 0 dopóki (i < 10) i ← i + 1 |
i = 0 while i < 10: i += 1 |
| Tablica/lista | x[1, 2, 3…, 10] dla i ← 0 do 9 wykonuj x[i] ← i |
x = [] for i in range(0, 10): x = i |
Dodatkowe informacje:
- W pseudokodzie i pythonie nie trzeba podawać typu zmiennej (deklaracja zmiennej i przypisanie).
- W obu językach używamy wcięć, aby zaznaczyć, że komenda tyczy się poprzedniej instrukcji (instrukcja warunkowa i porównanie).
- Należy pamiętać, że pętla w Pythonie to tak na prawdę iterator po elementach! Np. w przypadku iterowania po tablicy zamiast
range(10)wystarczy wpisać nazwę w tablicy i wtedy literaito pojedynczy element (pętla for). - W naszych programach będziemy też używać deklaracji funkcji.
Algorytmy sortowania

Iteracyjne
Sortowanie bąbelkowe
Iteracyjne algorytmy sortowania wykonują pewne kroki lub operacje w pętli. Charakteryzują się one efektywnością, powtarzalnością i szerokim zastosowaniem.
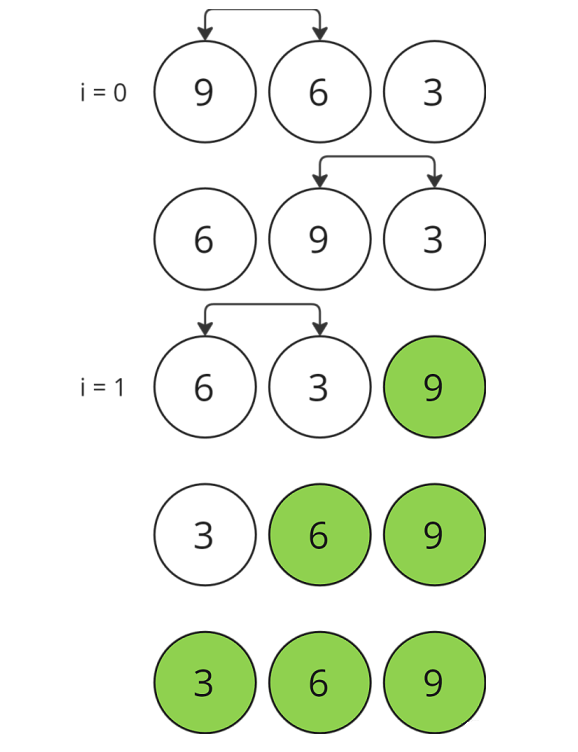
Sortowanie bąbelkowe to prosty algorytm sortujący używany w informatyce. Polega on na porównywaniu i zamianie miejscami kolejnych par elementów w liście tak długo, aż lista będzie uporządkowana.
Algorytm ten uzyskuje swoją nazwę od procesu "wypychania" większych elementów w górę, podczas gdy mniejsze elementy zostają na dnie (jak bąbelki w wodzie). Choć sortowanie bąbelkowe jest łatwe do zrozumienia i zaimplementowania, to mało wydajne i nieefektywne w przypadku dużych zbiorów danych.
Algorytm rzadko jest stosowany w praktyce, z wyjątkiem edukacyjnych przykładów.
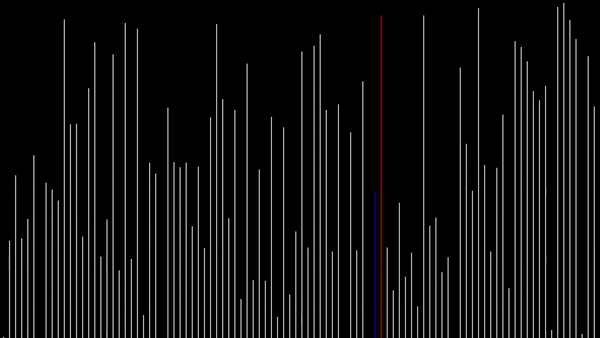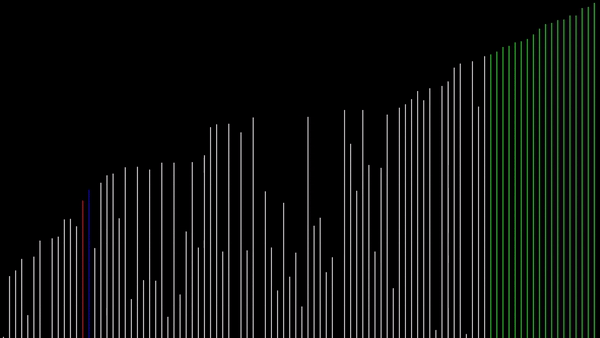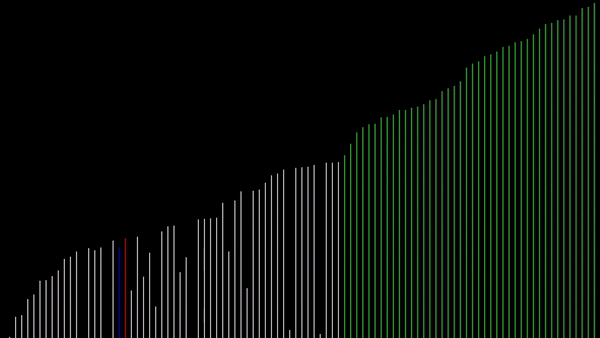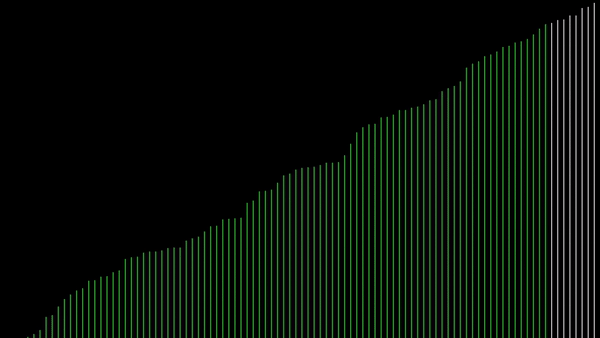
Sortowanie bąbelkowe w języku Python 3
def bubble_sort(array: list) -> None:
n = len(array)
for i in range(n):
# zakres pomija posortowane elementy
# odejmując ich indeksy i
for j in range(0,n-i-1):
if array[j] > array[j+1]:
# zamiana elementów w tablicach
array[j], array[j+1] = array[j+1], array[j]
return array
Złożoność czasowa
Algorytm ma złożoność czasową O(n2), gdzie "n" to liczba elementów w tablicy wejściowej. Wynika to z dwóch zagnieżdżonych pętli, wobec czego każda z nich w najgorszym wypadku wykonuje się "n" razy, czyli ostatecznie wykona się n * n operacji (n2).
Sortowanie kubełkowe
Jednym z ciekawszych i mniej znanych podejść jest sortowanie kubełkowe, które opiera się na zastosowaniu założenia, że jeśli zbiór elementów zostanie podzielony na mniejsze fragmenty (tzw. kubełki) i każdy z nich zostanie posortowany, to cały zbiór również zostanie uporządkowany.
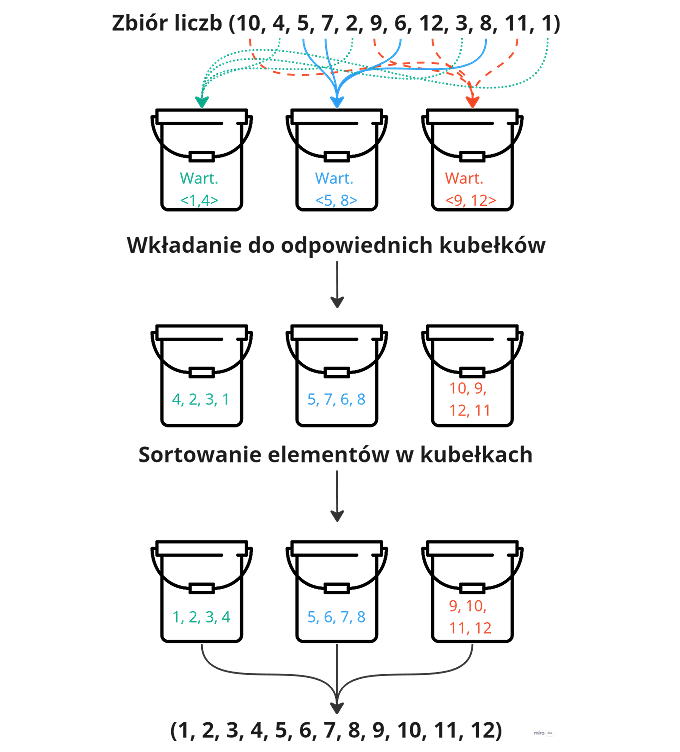
Algorytm polega na utworzeniu z góry założonej liczby kubełków. Każdemu kubełkowi ustalamy liczby, które będzie przechowywał. Aby to zrobić należy najpierw obliczyć zakres ze wzoru:
zakres = (max − min + 1) / lKub
gdzie:
min- najmniejszy element w zbiorze,max- maksymalny element w zbiorze,lKub- liczba utworzonych kubełków.
Następnie każdemu elementowi można przypisać odpowiedni kubełek:
nr = (el − min) / zakres
gdzie:
nr- numer kubełka do którego należy element zbioru,el- element zbioru.
Wynik należy zaokrąglić w dół.
Po przypisaniu elementów do kubełków należy każdy kubełek z osobna posortować i po posortowaniu "wypakować" elementy.
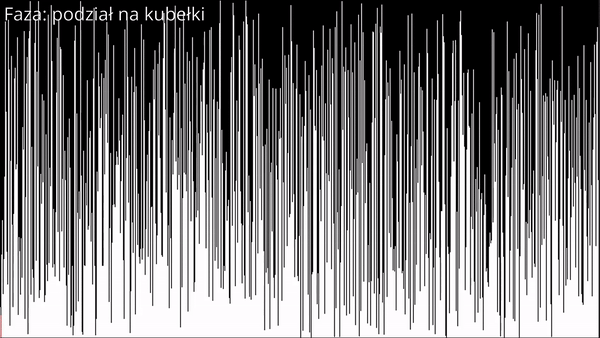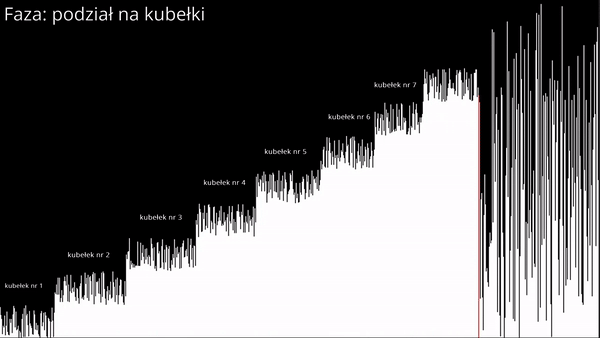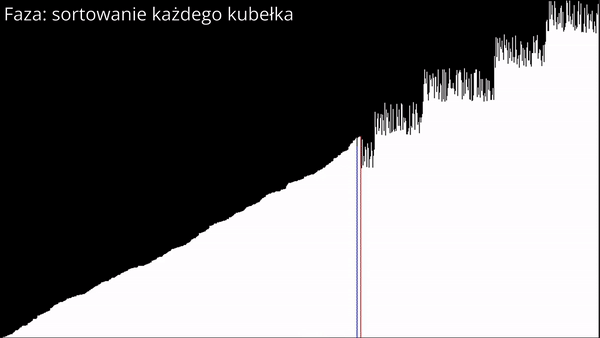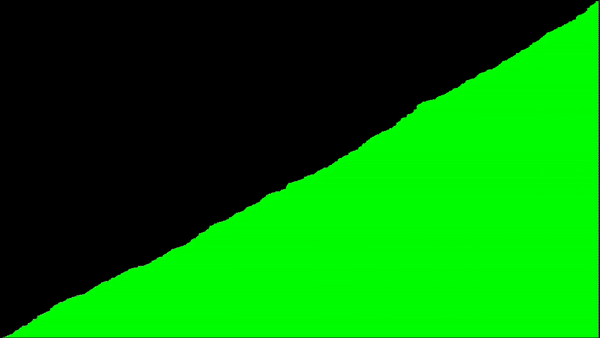
Sortowanie kubełkowe w języku Python 3
def bucket_sort(array: list) -> None:
numOfBuckets = 3
# deklaracja dwuwymiarowej listy (która przechowuje elementy w kubełkach)
buckets = [[] for _ in range(numOfBuckets)]
for el in array:
# zakres pojedynczego kubełka
bucketWidth = (max(array) - min(array) + 1) / numOfBuckets
# indeks kubełka do którego trafi element
bucketIndex = (el - min(array)) // bucketWidth
# przypisanie elementu do odpowiedniego kubełka
buckets[int(bucketIndex)].append(el)
# enumerate() podaje iterator, który zwiększa się z każdym krokiem pętli
for i, bucket in enumerate(buckets):
buckets[i] = sorted(bucket)
iterator = 0
for bucket in buckets:
for el in bucket:
array[iterator] = el
iterator += 1
Złożoność czasowa
Algorytm w przypadku średnim może pochwalić się złożonościąO(n + k). W najgorszym przypadku wyniesie O(n2).
Rekurencyjne
Funkcja rekurencyjna w swoim ciele wywołuje samą siebie. Tworzy niejako swoje kopie tylko z innymi parametrami, podczas gdy stworzone wcześniej wywołania nadal pozostają w pamięci. Taka funkcja musi mieć wbudowany warunek stopu na którym wywoływanie funkcji się skończy. Korzystanie z takiego rozwiązania może być nieefektywne wydajnościowo i pamięciowo. Dużą zaletą pisania rekurencji jest czytelność i elegancja kodu.
Sortowanie przez scalanie
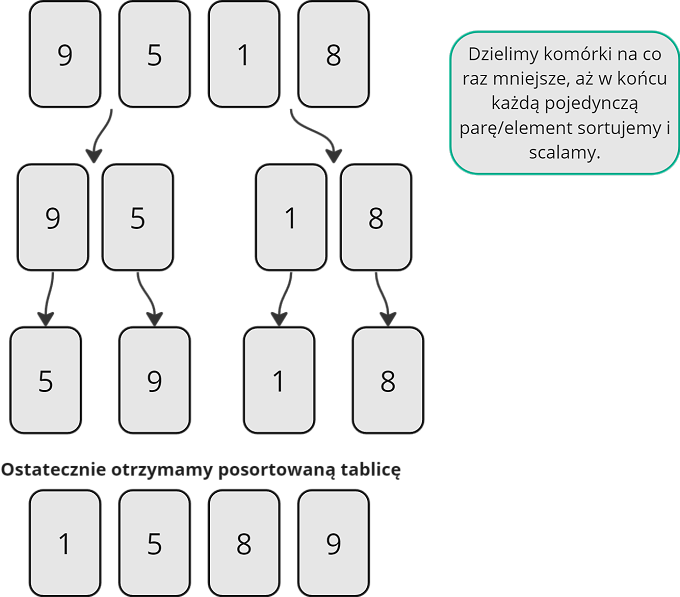
Sortowanie przez scalanie (ang. merge sort) to efektywny algorytm sortowania, który stosuje strategię "dziel i zwyciężaj". Działa na zasadzie dzielenia listy na mniejsze części, sortowania każdej z nich, a następnie scalania posortowanych podlist w jedną, posortowaną listę. Oto kroki algorytmu sortowania przez scalanie:
- Podział na mniejsze części:
- Podziel listę lub tablicę na dwie równe części. Możesz obliczyć środek listy jako
(lewy indeks + prawy indeks) / 2. - Rekurencyjnie podziel obie te części na jeszcze mniejsze części, aż każda z nich będzie składała się z pojedynczego elementu (lista jednoelementowa).
- Podziel listę lub tablicę na dwie równe części. Możesz obliczyć środek listy jako
- Sortowanie podlist:
- Kiedy zostaną utworzone jednoelementowe podlisty, zacznij je sortować. To jest podstawa "dziel i zwyciężaj".
- Sortuj każdą z podlist rekurencyjnie, używając tego samego algorytmu.
- Scalanie:
- Po posortowaniu dwóch podlist, scal je w jedną, zachowując porządek sortowania. Użyj dwóch wskaźników, jeden dla każdej z podlist oraz nową listę wynikową, na którą będziesz kłaść scalane elementy.
- Porównuj elementy wskazywane przez wskaźniki z obu podlist. Dodawaj mniejszy element do listy wynikowej i przesuwaj wskaźnik wskazujący na ten element w przód.
- Powtarzaj ten proces, dopóki nie wyczerpiesz elementów z obu podlist. Wówczas możesz dodać pozostałe elementy z niepustej podlisty do listy wynikowej.
- Kontynuuj scalanie:
- Powtarzaj kroki 3 dla wszystkich par podlist aż do momentu, gdy zostanie tylko jedna, posortowana lista.
- Zakończenie:
- Po scaleniu wszystkich podlist masz jedną posortowaną listę.

Sortowanie przez scalanie w języku Python 3
def merge_sort(array: list) -> None:
if len(array) <= 1:
return array
mid = len(array) // 2
# dzielimy tablicę na dwie podtablice: L i R
L = array[:mid]
R = array[mid:]
# wywołujemy rekurencyjnie merge_sort na obu podtablicach
L = merge_sort(L)
R = merge_sort(R)
# inicjalizujemy zmienne dla scalania tablic L i R, z wartościami 0
p = q = r = 0
# tworzymy nową tablicę do przechowywania posortowanych elementów
new_array = []
# scalamy podtablice L i R w jedną posortowaną tablicę new_array
while p < len(L) and q < len(R):
if L[p] <= R[q]: new_array.append(L[p])
p += 1
else:
new_array.append(R[q])
q += 1
r += 1
# jeśli w którejś z podtablic pozostały jeszcze
# elementy, dodajemy je do new_ar
while p < len(L):
new_array.append(L[p])
p += 1
r += 1
while q < len(R):
new_array.append(R[q])
q += 1
r += 1
return new_array
Złożoność czasowa
Algorytm sortowania przez scalanie ma złożoność czasową wynoszącą O(n log n), gdzie "n" to liczba elementów w tablicy wejściowej. Jest on stabilnym i efektywnym algorytmem.Sortowanie szybkie
Z sortowaniem szybkim wiąże się tzw. pivot. Wyobraź sobie, że jest to wskaźnik według którego będzie sortowany zbiór elementów. Jest on wybierany na starcie algorytmu. W większości przypadków jest środkowym elementem tablicy. Zamienia się go miejscem z ostatnim elementem tablicy.
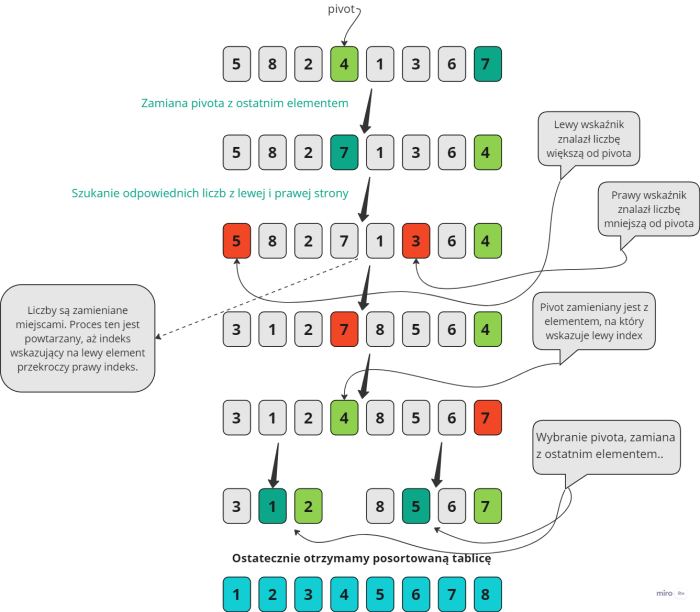
Następnie iteruje się po tablicy z lewej i prawej strony, aż do odnalezienia dwóch liczb:
- z lewej strony, która jest większa od pivota,
- z prawej strony, która jest mniejsza od pivota.
Po znalezieniu takich liczb zamienia się je miejscami i powtarza się proces rozpoczynając od indeksów, w których zamieniono 2 liczby.
Zatrzymuje się wykonywanie tej części, gdy lewy indeks wyprzedzi prawy. Innymi słowy wartość indeksu, który powinien wskazywać lewy element będzie większa od indeksu wskazującego prawy element.
Po zatrzymaniu się procesu, pivot zamienia się miejscem z indeksem wskazującym lewy element. W tym momencie pivot jest na swoim miejscu.
Ostatnim krokiem jest wywołanie dwóch funkcji sortowania (rekurencja) z nowymi parametrami. Do jednego wywołania przekazujemy indeksy wskazujące na pierwszy i ostatni element lewej, nieposortowanej części tablicy, a do drugiej - indeksy prawej, nieposortowanej części tablicy. Tym sposobem posortowane zostaną części tablicy na lewo i prawo od posortowanego pivota.
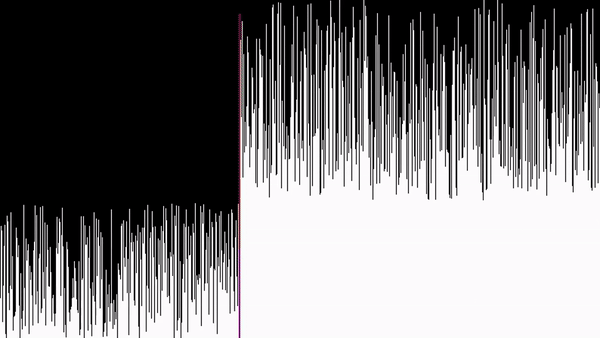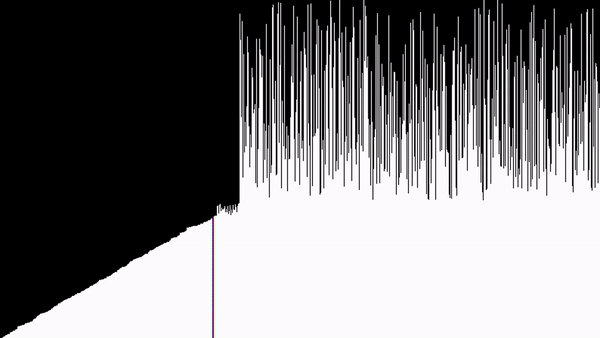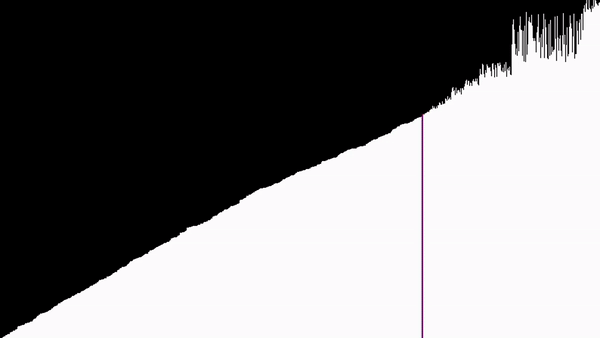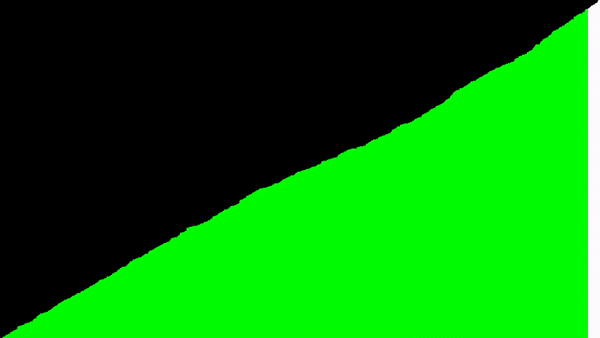
Na wizualizacji, na prawo od elementów, które się sortują, da się zauważyć górki - jeszcze nieposortowane elementy. Są to wcześniejsze wywołania funkcji sortowania. Można tu gołym okiem zobaczyć rekurencję.
Sortowanie szybkie w języku Python 3
def quick_sort(array: list, left: int, right: int) -> None:
if (left < right):
p = left
q = right
pivot = array[(left + right) // 2]
while (p <= q):
# szukanie lewego elementu, który jest większy od pivota
while (array[p] < pivot): p += 1
# szukanie prawego elementu, który jest mniejszy od pivota
while (array[q] > pivot): q -= 1
if p <= q:
# zamiana elementów, gdy są one niepoprawnie
# ułożone podczas partycjonowania
array[p], array[q] = array[q], array[p]
p += 1
q -= 1
# rekurencyjne wywołanie funkcji, aby posortować lewą część
quick_sort(array, left, q)
# rekurencyjne wywołanie funkcji, aby posortować prawą część
quick_sort(array, p, right)
Złożoność czasowa
Algorytm nie bez powodu nazywa się quick sort. Działa on bardzo szybko, a jego średnia złożoność czasowa to O(n log n). W przypadku pesymistycznym może wynieść O(n2).
Zadania do przećwiczenia

Zadanie 1
Napisz program, który przyjmuje od użytkownika listę liczb i sortuj ją rosnąco lub malejąco. Jeśli użytkownik wpisze literę "A" - to będzie rosnąco, w przypadku litery "D" malejąco. ("A" = ascending - rosnąco, "D" = descending - malejąco)
Przykład:
Dane wejściowe - dowolna tablica z liczbami, na przykład:
lista = [4, 9, 2, 1, 0, 5, 13, 11, 8, 3]- Typ sortowania = "D"
Oczekiwany rezultat:
posortowanaLista = [13, 11, 9, 8, 5, 4, 3, 2, 1, 0]
Zadanie 2
Napisz program, który posortuje zagnieżdżoną listę liczb wewnątrz głównej listy. W ten sposób chcemy uzyskać posortowaną listę, ale każda zagnieżdżona lista powinna zostać w tym samym miejscu.
Przykład:
Dane wejściowe - dowolna lista z listami, na przykład:
lista = [[5, 2, 9],[8, 1, 3],[7, 6, 4]]Oczekiwany rezultat:
posortowanaLista = [[2, 5, 9],[1, 3, 8],[4, 6, 7]]
Przykładowe zastosowanie sortowań na maturze z informatyki

Arkusz maturalny z informatyki - 7 czerwca 2018 r.
Link do danych, odpowiedzi i treści zadań
Odczyt danych
# tutaj należy pamiętać o podaniu prawidłowej ścieżki do plików!
files = [open('dane1.txt','r'),open('dane2.txt','r')]
# funkcja do otwierania i odczytu danych z pliku
def open_file(file):
# tymczasowa tablica na dane
temporaryArray = []
# odczyt wszystkich linii z pliku
lines = file.readlines()
for line in lines:
# rozdzielenie linii na pojedyncze liczby
singleNumbers = line.split()
# konwersja na liczby całkowite i dodanie ich do tablicy
temporaryArray.append([int(i) for i in singleNumbers])
return temporaryArray
# otwarcie i odczyt danych z plików
numbers1 = open_file(files[0])
numbers2 = open_file(files[1])
# zamknięcie obu plików po odczycie danych
files[0].close()
files[1].close()
(1) Przykładowe rozwiązanie podpunktu pierwszego
def solution_first_point():
correctLines = 0
for i in range(1000):
# porównanie ostatnich elementów z dwóch linii
if numbers1[i][-1] == numbers2[i][-1]:
correctLines+=1
return correctLines
(2) Przykładowe rozwiązanie podpunktu drugiego
# funkcja sprawdza, czy w liście jest dokładnie pięć liczb parzystych
def five_even(array):
return sum([i%2 for i in array]) == 5
def solution_second_point():
correctPairs = 0
# iteracja po odpowiadających sobie listach z numbers1 i numbers2
for num1, num2 in zip(numbers1, numbers2):
# sprawdzenie, czy obie listy zawierają dokładnie 5 liczb parzystych
if five_even(num1) and five_even(num2):
correctPairs+=1
return correctPairs
(3) Przykładowe rozwiązanie podpunktu trzeciego
def solution_third_point():
correctPairs = 0
rows = []
for i in range(1000):
# porównanie zbiorów elementów z dwóch linii
if set(numbers1[i]) == set(numbers2[i]):
correctPairs+=1
# dodanie numeru wiersza (numeracja od 1) do listy
rows.append(i+1)
return correctPairs,rows
(4) Przykładowe rozwiązanie podpunktu czwartego
def merge_sort(array):
if len(array) <= 1:
return array
mid = len(array) // 2
L = array[:mid]
R = array[mid:]
L = merge_sort(L)
R = merge_sort(R)
p = q = r = 0
new_array = []
while p < len(L) and q < len(R):
if L[p] <= R[q]:
new_array.append(L[p])
p += 1
else:
new_array.append(R[q])
q += 1
r += 1
while p < len(L):
new_array.append(L[p])
p += 1
r += 1
while q < len(R):
new_array.append(R[q])
q += 1
r += 1
return new_array
def solution_fourth_point():
temporaryArray = []
for i in range(1000):
# połączenie dwóch list liczbc w jedną
array = numbers1[i] + numbers2[i]
# dodanie posortowanej listy do wynikowej tablicy
temporaryArray.append(merge_sort(array))
# konwersja wynikowej tablicy posortowanych list na tekstową
# reprezentację z odpowiednimi odstępami i znakami nowej linii
return '\n'.join(' '.join([str(j) for j in i]) for i in temporaryArray)
Przykładowe wywołanie rozwiązań
if __name__ == '__main__':
answer_first_point = solution_first_point()
answer_second_point = solution_second_point()
answer_third_point = solution_third_point()
answer_fourth_point = solution_fourth_point()
UWAGA! Chcąc odtworzyć u siebie rozwiązanie, należy pamiętać o odpowiedniej ścieżce, w której znajdują się dane.
Zakończenie
Jest wiele algorytmów sortowania, a my przedstawiliśmy tylko cztery z nich. Niektóre charakteryzują się wolnym działaniem, inne wręcz przeciwnie - są szybkie i efektywne.
Pamiętać trzeba, że każdy algorytm może służyć do czegoś innego:
- Sortowanie bąbelkowe może zadowalająco działać na małych zbiorach liczb.
- Sortowanie kubełkowe najlepiej stosować, gdy dane do posortowania są równomiernie rozłożone w pewnym zakresie i zakres wartości danych jest niewielki w porównaniu do ilości elementów.
- Sortowanie szybkie działa świetnie na średnich i dużych zbiorach danych. Pamiętać jednak trzeba, że to algorytm rekurencyjny i może zużywać dużo pamięci.
- Sortowanie przez scalanie stosuje się na dużych zbiorach danych i jest on stabilnym algorytmem.
Wiele języków programowania ma wbudowaną funkcję sortowania. Np. Python posiada funkcję sorted().
Bibliografia
- https://github.com/Equerm8/visualizer_of_sorting_algorithms
- https://pixabay.com/pl/users/mohamed_hassan-5229782/
- https://www.freecodecamp.org/news/all-you-need-to-know-about-big-o-notation-to-crack-your-next-coding-interview-9d575e7eec4/
- https://pub.towardsai.net/big-o-notation-what-is-it-69cfd9d5f6b8


Komentarze
Czy macie jakieś pytania, sugestie, uwagi? A może zauważyliście literówkę albo błąd? Dajcie koniecznie znać: kontakt@pasja-informatyki.pl. Dziękujemy za poświęcony czas - to dzięki Wam serwis staje się coraz lepszy!